
Managing technical SEO for a massive website with over one million URLs is an entirely different challenge compared to smaller websites. At this scale, even the slightest inefficiency in crawling, indexing, or rendering can significantly affect the site's visibility in search engines. Therefore, ensuring a robust and well-optimized technical SEO foundation is crucial to maintaining organic performance and allowing search engines to effectively discover and prioritize your content.
In this article, we’ll go over the top technical SEO checks that are particularly important for enterprise-scale websites. Whether you're dealing with millions of product pages, forum entries, or news articles, the following strategies will help you streamline SEO processes, minimize issues, and make better use of search engine resources.
1. Crawl Budget Optimization
Search engines allocate a finite number of pages they will crawl on a particular site over a certain timeframe. When working with massive websites, it becomes imperative to use this crawl budget efficiently.
- Block low-value pages using robots.txt — Pages like admin panels, search result pages, or duplicate tag pages should be blocked if they're not of SEO value.
- Use noindex tags — When you don't want a page to appear in Google’s index but still need it accessible to users and bots.
- Fix redirect chains — Multiple redirect hops slow down crawlers and can lead to premature crawl budget exhaustion.
- Consolidate duplicate URLs with canonical tags.
Crawl budget becomes a bottleneck quickly on large sites — regularly monitor your crawl stats using Google Search Console and server logs to identify patterns and areas for improvement.
2. Scalable URL Structure
Having a well-structured URL format is not only good for usability but also helps search engines understand website hierarchy and relevance. With over a million URLs, bots need to make sense of which pages are top-level and which ones are deeply nested content.
- Use semantic paths in your URLs (e.g., /category/product-name).
- Avoid URL parameters that create infinite crawl spaces like sessionIDs or filters.
- Establish breadcrumb URLs where appropriate to reinforce internal linking hierarchy.
Also, ensure your internal links reflect your preferred canonical URL structures and avoid linking to tracking or parameterized versions unnecessarily.
3. XML Sitemaps: Segmentation and Prioritization
Large-scale sites need a sitemap strategy that mirrors their complexity. Google can only consume up to 50,000 URLs per sitemap file or a 50MB uncompressed file size, whichever comes first. Therefore, segmented sitemaps are a must.
Consider organizing your sitemaps by:
- Content type (e.g., blog posts, product pages, news)
- Update frequency (e.g., daily updated vs. static pages)
- Top-performing categories or products
Update only what’s changed to reduce server load and highlight freshness. Use the sitemap index file to reference all individual sitemaps and submit it in Search Console.
Include only indexable and high-value URLs in your sitemaps. Avoid errors and ensure lastmod fields are accurate to highlight recent updates to search bots.
4. Duplication Control Using Canonicals & Hreflang
When you have millions of pages, content duplication becomes almost inevitable — whether through user-generated filters, variations by region or language, or minor structural differences. Poor duplication control can dilute rankings and waste crawl budget.
Use:
- Rel=canonical to declare the preferred version of a page
- Rel=alternate hreflang for different regional or language variants of content
- Consistent internal anchors that point to canonical versions
Double-check that canonicals are self-referencing when they should be and that hreflang annotations are bi-directional and valid. Invalid hreflangs can confuse, rather than assist, search bots.
5. Load Performance and Core Web Vitals (CWV)
Page speed and user experience heavily influence how well large websites perform in SERPs. Once a site gains scale, keeping performance consistent across vast numbers of templates and resources becomes a significant challenge.
Focus on:
- Deferring or lazy-loading unnecessary scripts
- Optimizing images and serving them in next-gen formats
- Using CDNs to deliver static content
- Ensuring mobile-first design and usability
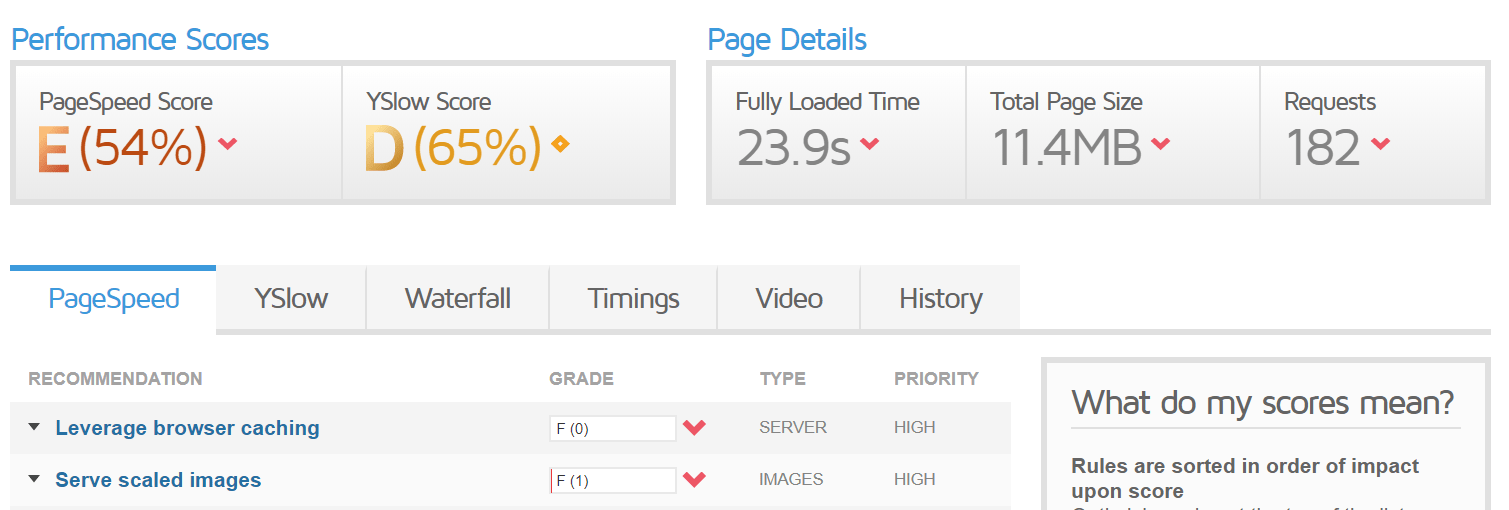
Use Lighthouse audits, PageSpeed Insights, and Chrome UX Reports to continually monitor and refine your Core Web Vitals metrics — specifically LCP (Largest Contentful Paint), FID (First Input Delay), and CLS (Cumulative Layout Shift).
6. Log File Analysis for Crawl Insights
To truly understand how search engines are interacting with your massive website, parsing and analyzing server log files is indispensable. Logs reveal which pages are being crawled, how often, and how consistently.
This helps identify:
- Wasted crawl budget on low-value pages
- Crawl anomalies like spikes or dead ends
- Pages receiving high crawl rates but low conversions or indexing reach
Use log analyzers or custom tooling to parse logs and match them against internal URL lists and sitemap references. Tools like Screaming Frog Log File Analyzer or Botify can handle these at scale.
7. Scalable Internal Linking
Internal linking structure can dramatically influence which pages are prioritized by crawlers. You want to strategically route internal equity and ensure that deep or newer pages aren’t stranded or buried.
Effective strategies include:
- Dynamic footer or sidebar links for key categories
- Automated related-content modules
- Breadcrumb trails and hierarchical nav systems
Ensure that high-performing or business-critical pages receive sufficient internal link juice and are not more than a few clicks deep from the homepage or major navigational points.
8. Dealing with Orphan Pages
Orphan pages — URLs that exist but have no internal links pointing to them — are surprisingly common in large sites, especially those using dynamic generation or third-party CMS integrations.
If not found through the sitemap or external links, search bots may never discover these pages. Use log files + crawling tools to detect orphan pages and reintegrate them into the internal linking web or mark them as noindex if they're irrelevant.
9. Structured Data at Scale
For a site of this size, structured data implementation needs to be consistent and validated to avoid schema markup errors or spam signals.
Popular schema types include:
- Product — with availability, price, and review fields
- Article — with author, datePublished, headline
- Breadcrumb — to boost search result snippets
Use batch validators and schema testing APIs to validate structured data in bulk. Ensure that markup is not only present but accurate and reflective of the visible page content.
10. Error and Status Code Monitoring
Constantly monitor for broken links, 404 errors, 5xx errors, and other status code anomalies which can hurt crawlability and user experience.
Best practices:
- Automatically generate 404 reports and monitor in GSC and analytics
- Use custom response pages with helpful navigation or search bar
- Ensure your server uptime and response times are stable and monitored continuously
Additionally, implement monitoring systems to catch unexpected redirect loops, protocol mismatches (HTTP vs HTTPS), and redirects to non-canonical domains.
Conclusion
Technical SEO for websites with over 1 million URLs is not about checking off a few boxes—it's about creating scalable, monitorable systems that can adapt as your site grows. By implementing the strategies listed above—from crawl budget preservation to log analysis and internal linking—you create


